For my Master’s thesis I extended a 3d object detection and localization framework to leverage positive context clues by integrating scene appearance information. My experimental results achieved state-of-the-art performance with a significant improvement over prior results (Song et al, Ren et al).
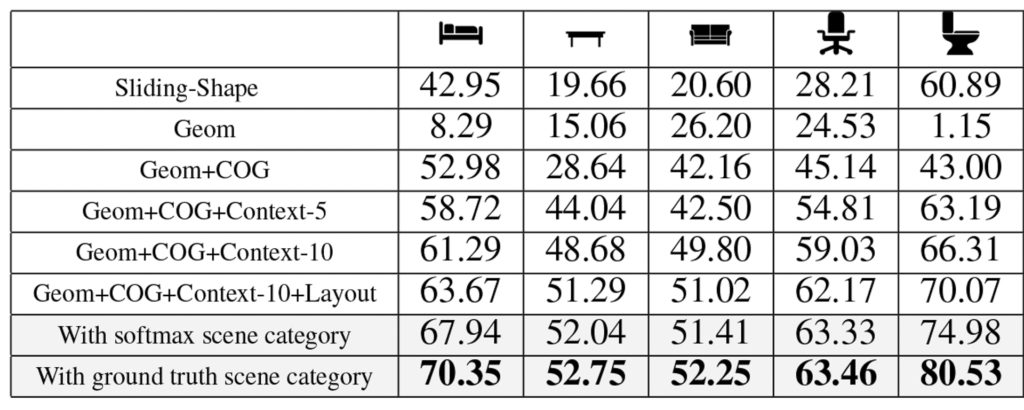
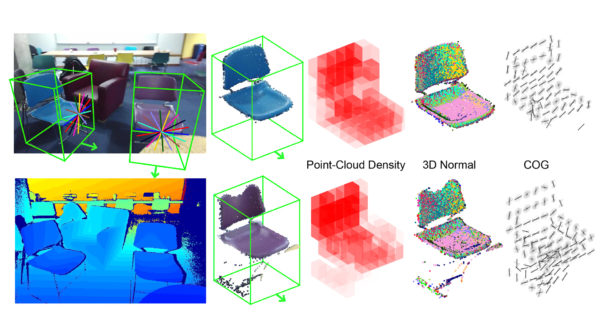
Prior to writing my thesis I had been doing research with Dr. Zhile Ren and Prof. Erik Sudderth at Brown University on the aforementioned 3d object detection and localization framework. Given input RGB-D images of indoor scenes we were able to achieve state-of-the-art performance, as shown in the third to last row (Geom+COG+Context-10+Layout) in the figure above.

Besides a novel image feature called “Clouds of Oriented Gradients”, much of the performance improvement stemmed from spatial context features. These features modeled the spatial relationship between object detections themselves and the estimated room layout, greatly reducing the number of false positives (compare the last column of the figure above with the inner two columns).
Knowing the importance of contextual clues and given my experience with image understanding, I decided to try integrating scene appearance information into the 3d object detection and localization framework. My hypothesis was that incorporating contextual clues about scene appearance information (i.e does the room look like a bedroom or a bathroom) would improve performance for object categories that mostly appear in certain types of rooms (i.e beds in bedrooms, toilets in bathrooms).
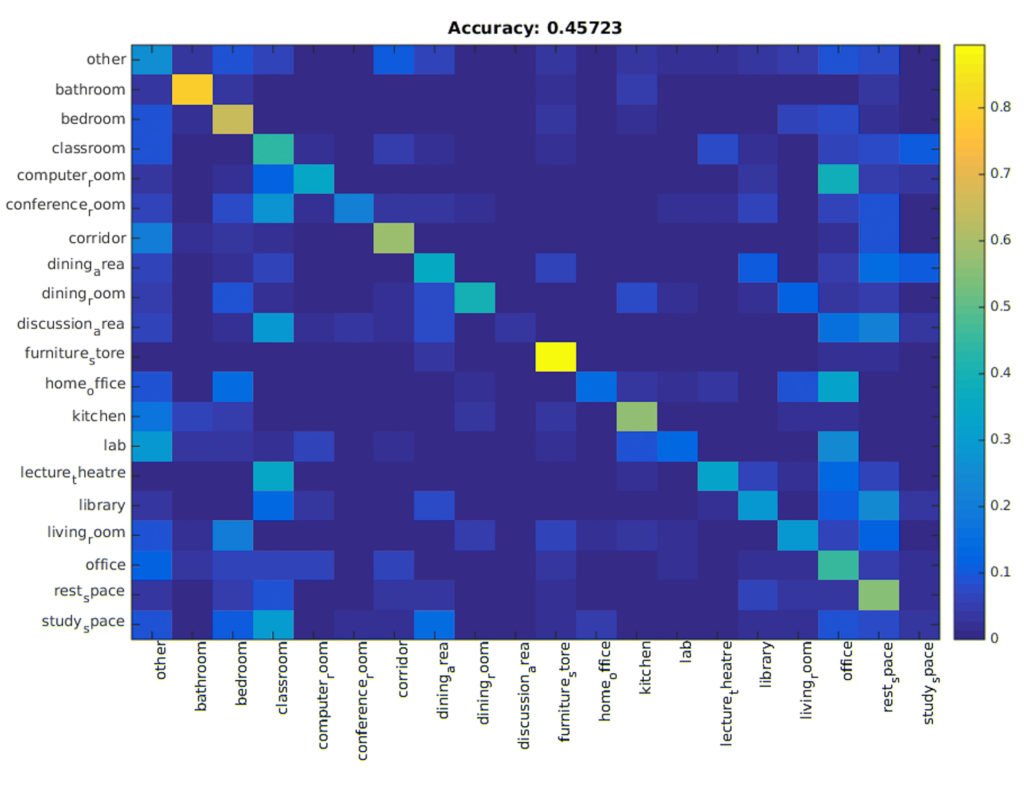
To leverage positive context clues and integrate scene appearance information into the 3d object detection and localization framework I first trained a linear SVM to classify scene category using 2d image features pre-computed using MIT’s Places-CNN. This scene category classifier classified scenes into 20 categories (bathroom, bedroom, etc) and achieved a state-of-the-art scene categorization accuracy of 45.72% versus 39.00% of prior work (Song et al).
I then used this scene category classifier to create a new 2d scene appearance feature over the 20 scene categories that I fed into the 3d object detection and localization framework. In addition to this new softmax scene category feature I also created a one-hot scene category feature using the ground truth to test the potential improvement possible.
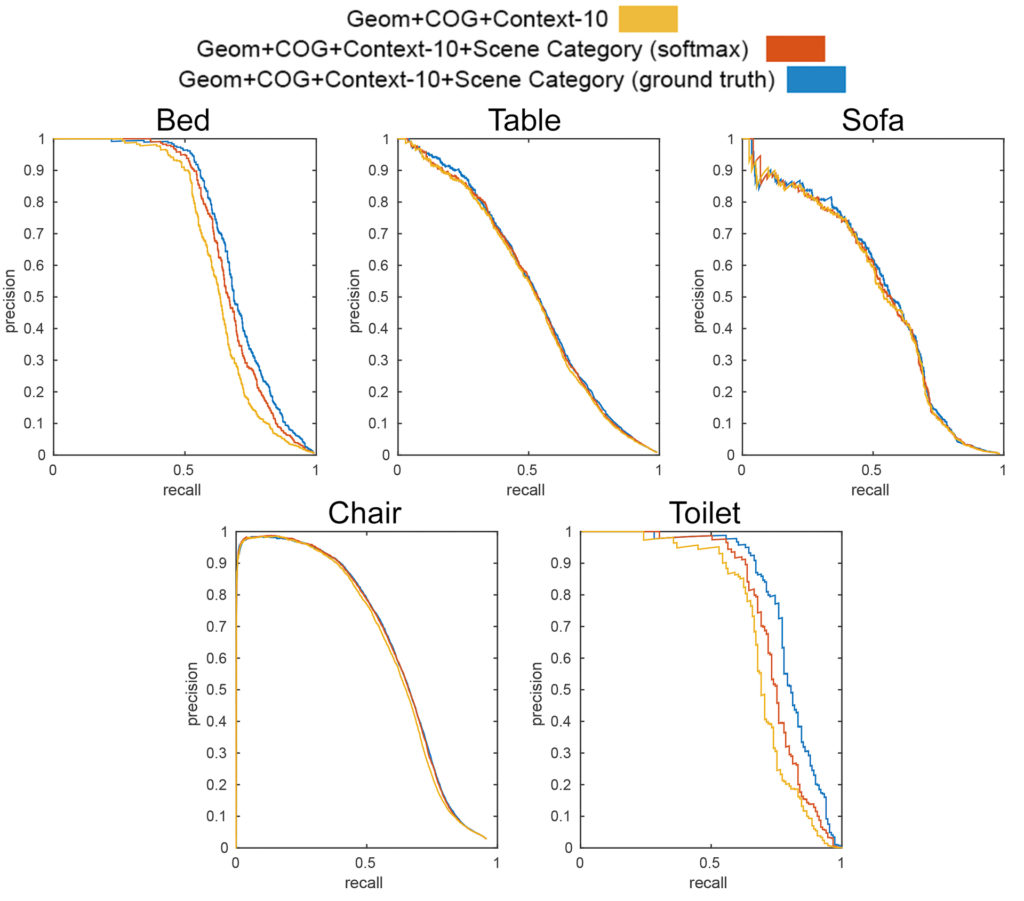
As seen in the figure above and the results table at the top, both the softmax scene category feature and ground truth one-hot scene category feature outperformed prior work by a significant margin. Object categories that have strong contextual relationships with scene category (beds, toilets, and bathtubs) showed the most improvement while all other categories showed some improvement.
You can view all the results and the whole paper here!